

context
Developed by Georgia Tech Ubiquitous Computing Group and funded by Oracle, IMUTube is an automatic processing pipeline that extracts virtual streams of inertial measurement unit (IMU) data from YouTube videos for human activity recognition (HAR). This large-scale labelled dataset can be used to support research in HAR such as detecting mental and physical health and understanding human behaviors. The goal for this project is to create a platform for researchers who may not a have programming background to easily use this pipeline.

more context on IMUTube
This ongoing machine learning project extracts wearable sensor-based data from YouTube videos. Collecting and processing data is extremely time-consuming and expensive, and this pipeline allows researchers studying human behaviors to easily access large-scale labeled data sets.

input video
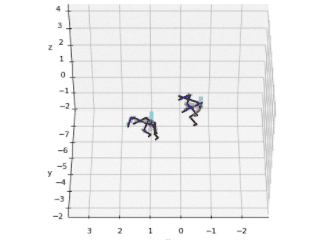
3D reconstruction

Virtual Sensor
IMUTube processes target human activities from input videos into virtual IMU dataset that researchers can investigate further to learn more about human behaviors.
what was the problem were we trying to solve?
How might me we make wearable sensor-based data more accessible to researchers who might not have programming skills?
problems
Problem #1: Lack of accessibility to researchers without programming skills
While this pipeline can serve as a great resource for many researchers studying human behaviors, it requires programming skills to retrieve data because the video URLs and data parameters have to be hard-coded. The new platform should allow researchers without programming skills to easily navigate and access data.
Problem #2: Lack of flexibility in input options
Researchers need the flexibility to input multiple target activities and different data parameters for each activity, which can be redundant and inefficient. The new platform should provide flexibility by allowing multithreading when inputting data parameters.
Problem #3: lack of recoverability
The current system requires users to hard code the parameters and repeat the process all over again if users make an error. We want the new platform to allow recovery and users to easily go back and fix their errors.
iterating
To address the key problems identified, we developed a high-level user flow to outline the process and created low-fidelity wireframes for early-stage testing. These wireframes were used in user research sessions to gather feedback on the core functionality and usability of the solution. The iterative approach allowed us to refine the design based on real user input, ensuring alignment with user needs and goals.


user feedback
from lo-fi user testing
1
Guide users through the process
Users who are not familiar with the IMU pipeline had a difficult time navigating without any instructions.
2
Provide more flexibility in selecting parameters
By streamlining the UI and minimizing visual clutter, the redesign puts video content front and center. This "content-first" approach emphasizes TikTok's core value: providing engaging and entertaining video content.
3
Provide video details
Users needed more information about the videos before selecting (title, length, preview).
4
Show progress
Users wanted more operation visibility through a progress bar.
final design





01.
target activity searchperience
Researchers are able to select multiple target activities.
02.
Inconsistencies in key components
Researchers define activity parameters for each target activity by selecting height and BMI range and placing sensors on the interactive 3D body model.


03.
Too many distracting visual elements
Researchers enter video parameters such as human tracking per video, duration, resolution, number of videos.
04.
Poor responsiveness
Researchers select videos for imu processing for each target activity. They are able to preview before selecting videos.


03.
Downloads
Downloaded data sets are organized by activity categories.
Monica Jeon 2026
all projects